ESXi 紫屏
ESXi 紫屏死机(Purple Screen of Death,简称 PSOD)是 VMware ESXi 系统遇到严重错误时显示的紫色错误界面,类似于 Windows 的蓝屏死机。
紫屏类比于程序员写代码,跑起来全是红色警告。起初陈大剩遇到有点慌,当遇到多了,也就习惯了,先记录一下,再看是什么原因。
什么是 ESXi 紫屏¶
ESXi 紫屏是 VMware 虚拟化平台的内核级错误显示机制,当系统遇到无法恢复的严重错误时会触发。
紫屏死机影响
- 虚拟机停止:所有运行中的虚拟机立即关闭
- 数据丢失风险:未保存的虚拟机数据可能丢失
- 服务中断:整个虚拟化环境不可用
- 系统重启:ESXi 主机自动重启
陈大剩遇到的紫屏¶
不得不说陈大剩遇到的紫屏还真不少,此处列举几个常遇到的紫屏,遇到先记录下来。
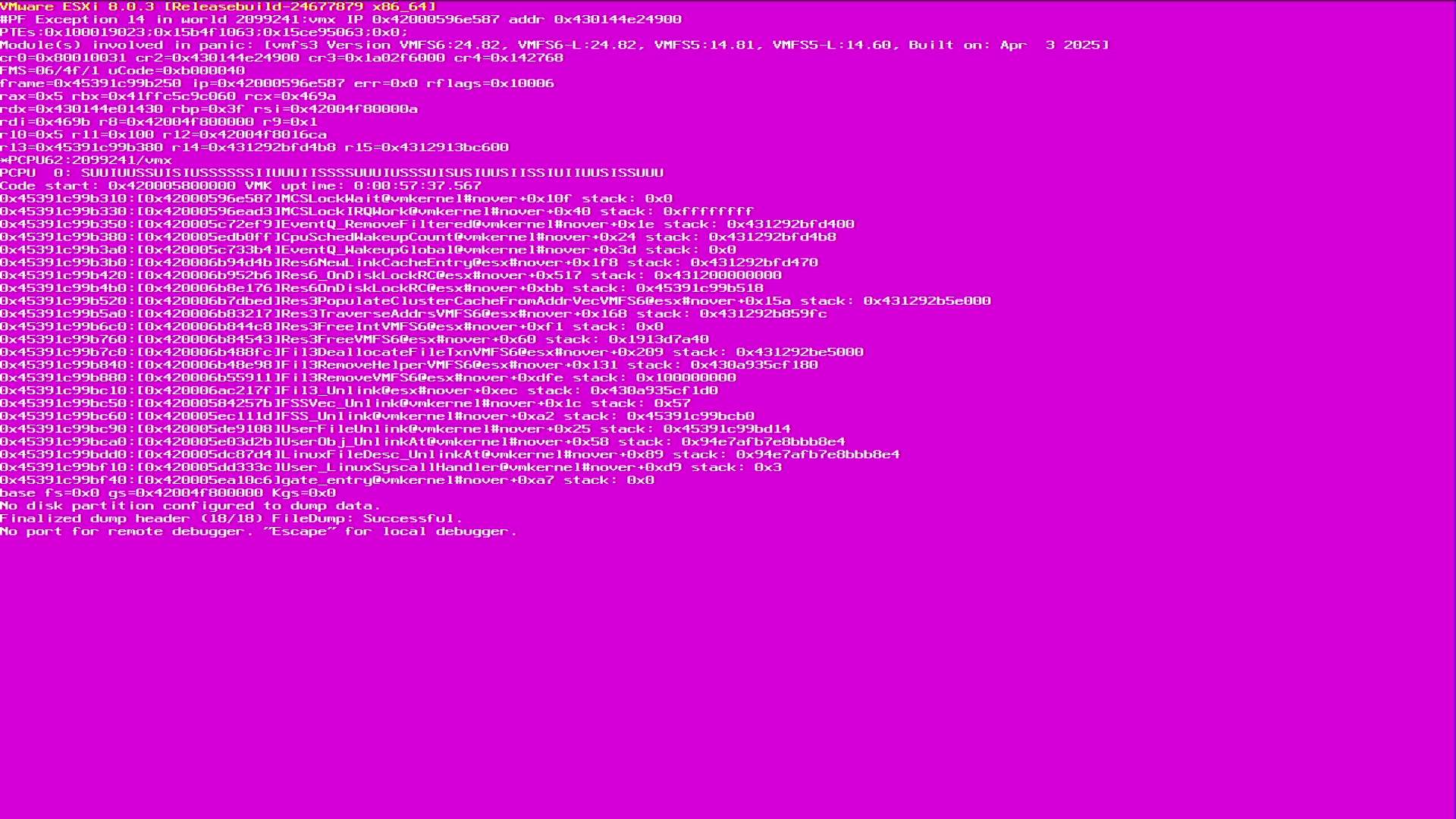
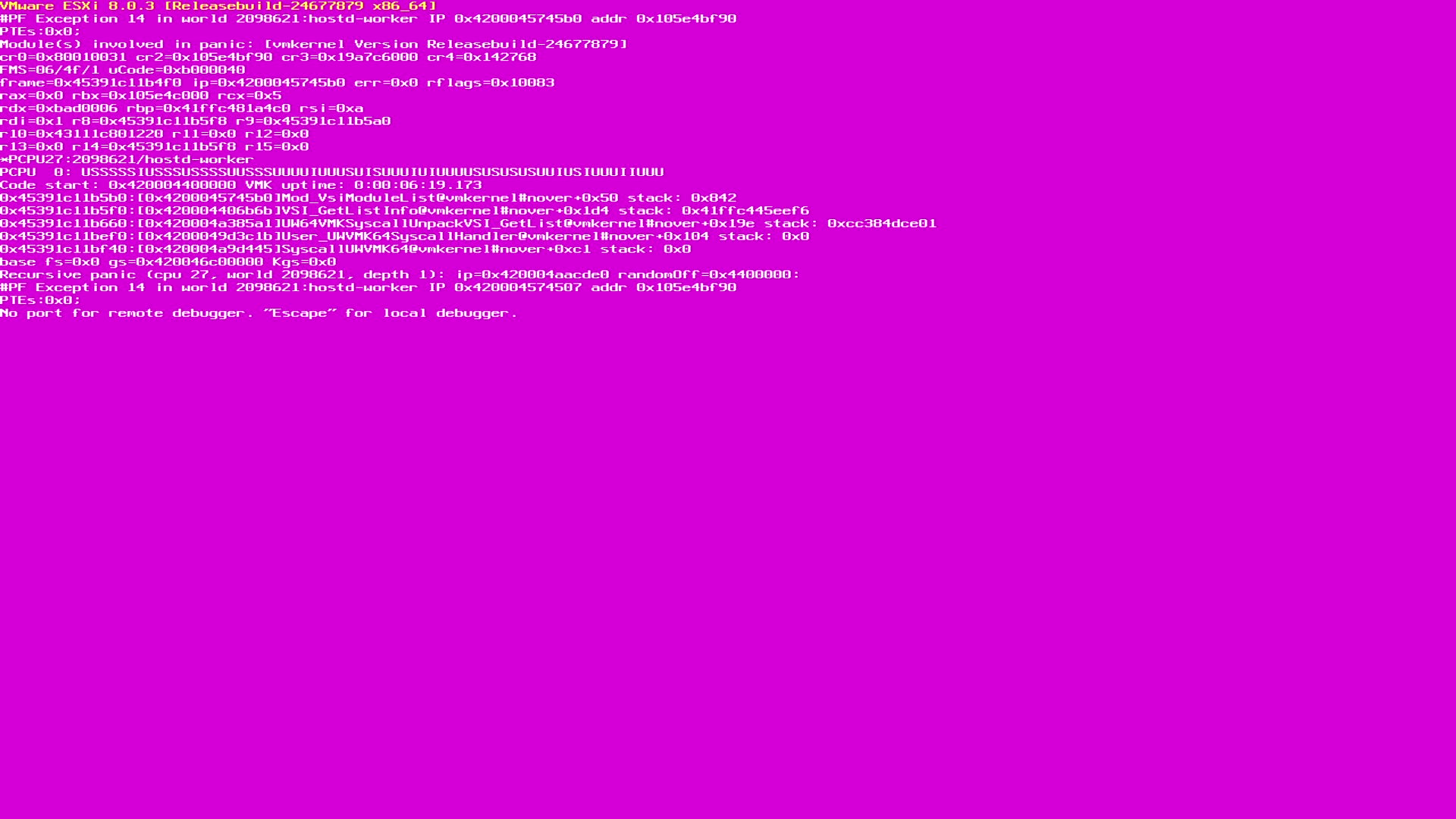
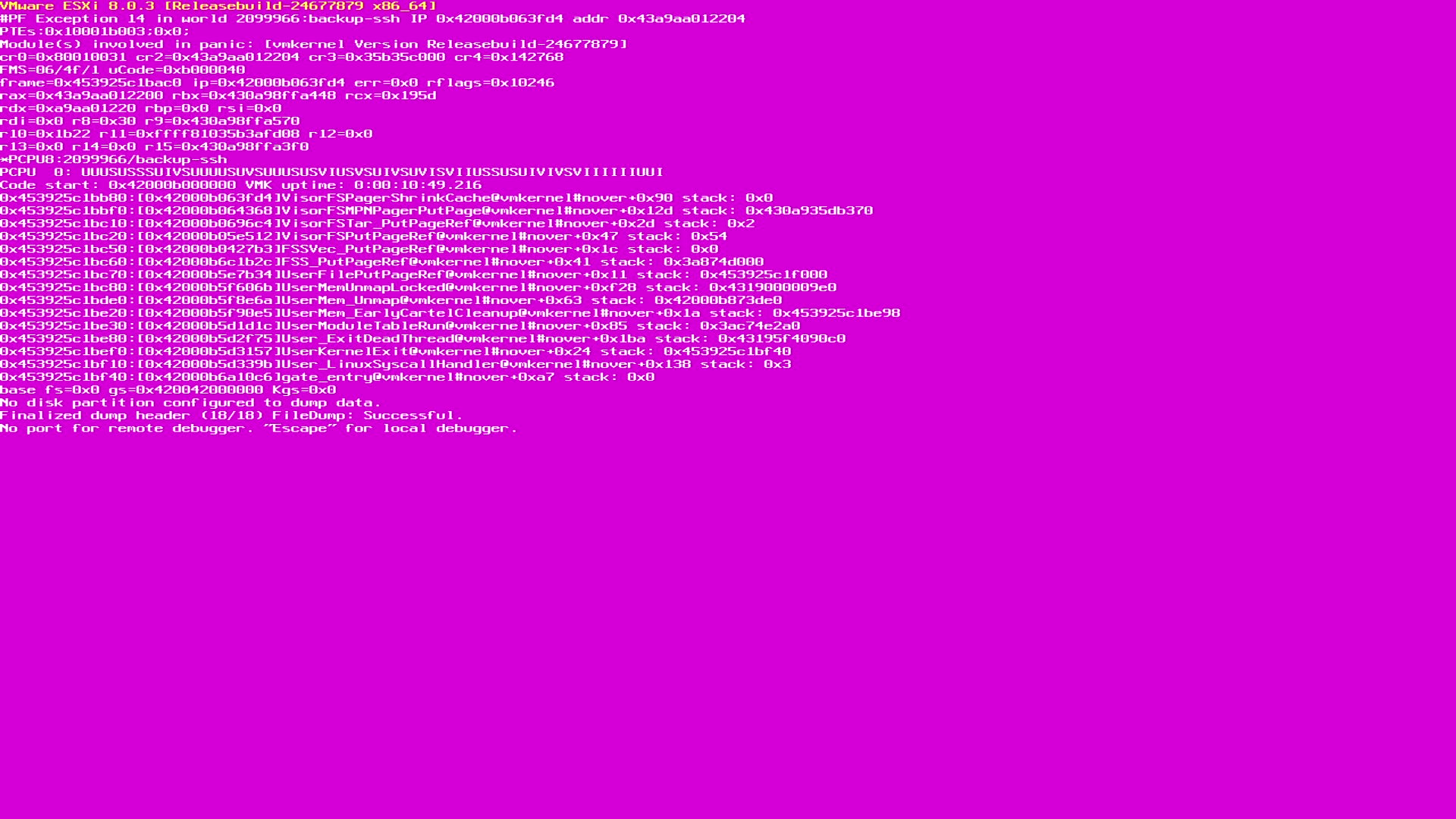
紫屏信息解读¶
陈大剩用一个图来解释一下紫屏的信息,通过 ESXi 紫屏信息,可以看到具体的使用状态:
ESXi 8.0.3 版本,架构为 x86_64,错误类型为 PF Exception 14,世界 ID 为 2099241,问题标签为 vmx,涉及模块包括:xxxx。
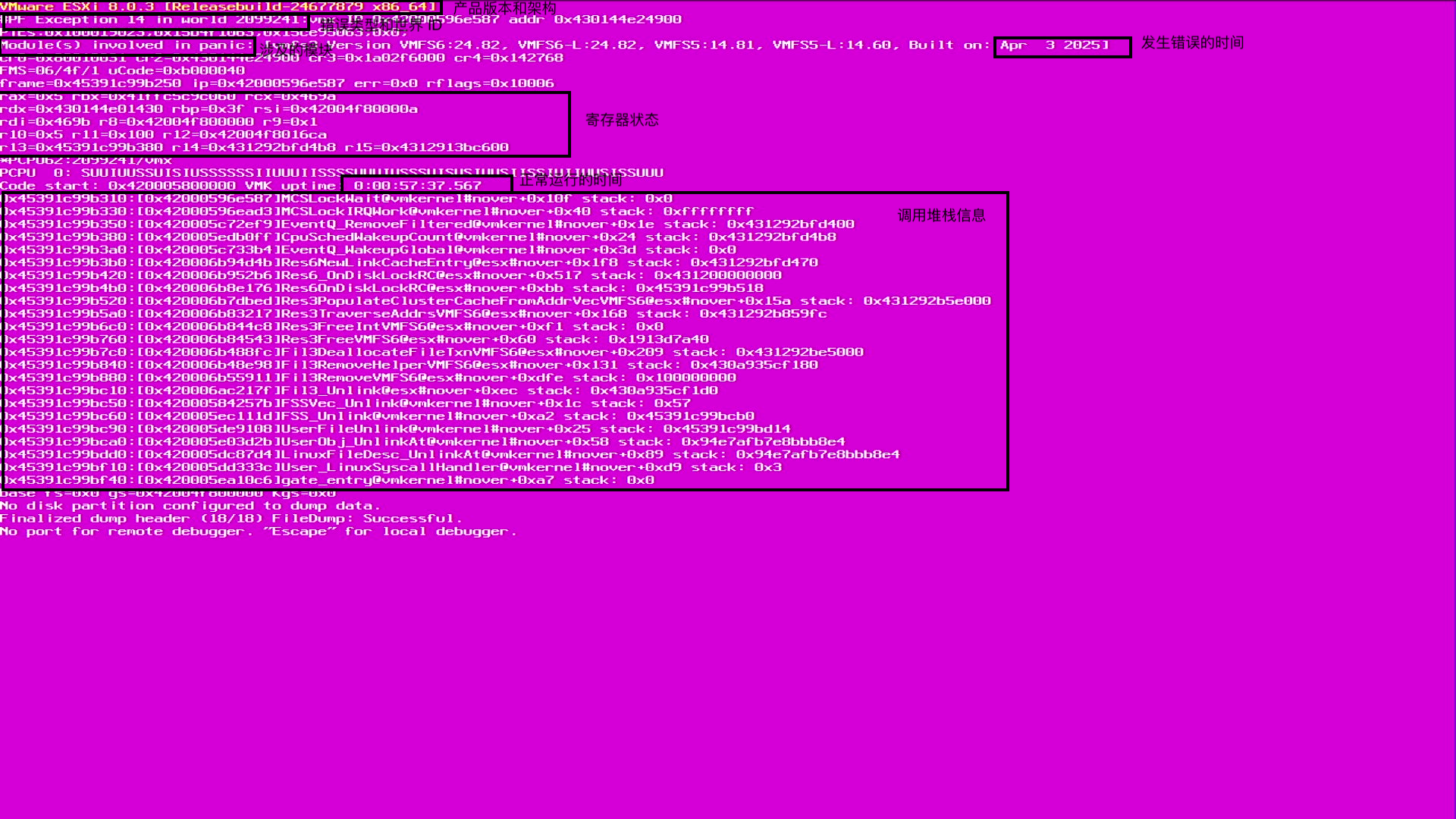 从图上我们只能看出是
从图上我们只能看出是 vmx 相关问题 ,并不能看出什么来,向这种问题就需要向 VMware 官方资源 去搜索或提问了。
基本信息结构¶
此处陈大剩将 ESXi 紫屏重点信息关键信息,列举一下:
# 错误类型和世界 ID
#PF Exception 14 in world 12345:vmm0
# 错误发生地址
@ 0x41800123abc
# 寄存器状态
RAX: 0x0000000000000000 RBX: 0x1234567890abcdef
RCX: 0x0000000000000001 RDX: 0x0000000000000000
# 调用堆栈
Backtrace:
0x41800123abc [vmkernel]
0x41800456def [vmkernel]
0x418007890ab [driver_module]
常见错误类型¶
| 错误代码 | 错误名称 | 主要原因 | 严重程度 |
|---|---|---|---|
| #PF Exception 14 | 页面错误 | 内存访问错误、驱动问题 | 高 |
| #GP Exception 13 | 通用保护错误 | 硬件兼容性、驱动冲突 | 高 |
| NMI Exception | 不可屏蔽中断 | 硬件故障、内存错误 | 极高 |
| MCE Exception 18 | 机器检查异常 | CPU、内存硬件错误 | 极高 |
| ASSERT Failed | 断言失败 | 软件缺陷、配置错误 | 中 |
关键字段含义¶
世界 ID(World ID):
vmm0: 虚拟机监视器console: 管理控制台net-XXX: 网络相关进程scsi-XXX: 存储相关进程
信息记录建议
- 拍照保存:紫屏信息会在重启后消失
- 记录完整信息:包括错误代码、地址、调用堆栈
- 注意时间:记录故障发生的具体时间
本文只挑选了关键部分讲解,细致的讲解可参考官方文章:Interpreting a host purple diagnostic screen,需要一些英文基础。
检查方法步骤¶
步骤 1:获取核心转储文件¶
ESXi 紫屏发生后,系统会生成核心转储文件用于详细分析:
查找转储文件位置:
导航路径:【主机】→【监控】→【日志】,具体日志每个日志代表什么,可在 步骤 2:分析系统日志 分析。
如果网络不可用,可通过 DCUI(直连用户界面):
- 在 ESXi 主机控制台按 F2
- 输入 root 密码登录
- 选择【View System Logs】
- 选择【vmkernel.log】查看错误信息
步骤 2:分析系统日志¶
关键日志文件:
# 主要系统日志
/var/log/vmkernel.log # 内核日志(最重要)
/var/log/messages # 系统消息
/var/log/hostd.log # 主机守护进程日志
/var/log/vpxa.log # vCenter 代理日志
# 查看日志的时间范围(紫屏前后 30 分钟)
grep -A 10 -B 10 "Exception\|PSOD\|panic" /var/log/vmkernel.log
日志分析示例:
# 示例:内存相关错误
2024-01-15T14:32:15.123Z cpu4:12345)WARNING: Heap: 2976: Heap_Align(memMap/2):
Alignment 4096 not supported for size 2048
# 示例:硬件错误
2024-01-15T14:32:20.456Z cpu0:12345)NMI: 1234: NVRAM: Non-Fatal Error in DIMM_A1
Single-bit ECC error detected
# 示例:驱动问题
2024-01-15T14:32:25.789Z cpu2:12345)WARNING: vmkapi: 1234: Invalid parameter
passed to vmk_PktList API
步骤 3:硬件健康检查¶
CPU 状态检查:
# 检查 CPU 信息和错误
esxcli hardware cpu list
esxcli hardware cpu cpuid get
# 查看 CPU 温度和频率
vsish -e get /hardware/cpu/cpuList/
内存状态检查:
# 内存信息概览
esxcli hardware memory get
# 内存插槽详细信息
smbiosDump | grep -A 20 "Memory Device"
# ECC 错误统计
vsish -e get /hardware/memory/
存储健康检查:
# 存储适配器状态
esxcli storage core adapter list
# 磁盘健康状态
esxcli storage core device list
esxcli storage nmp device list
# SMART 信息检查
esxcli storage core device smart get -d <device-name>
步骤 4:网络和PCI设备检查¶
网络设备状态:
# 网络适配器列表
esxcli network nic list
# 网络驱动信息
esxcli network nic get -n vmnic0
# 网络错误统计
esxcli network nic stats get -n vmnic0
PCI 设备状态:
常见故障原因及解决¶
硬件相关问题¶
症状特征:
- 错误代码:
#PF Exception 14、NMI Exception - 日志关键词:
ECC error、Memory、DIMM
检查方法:
解决方案:更换故障内存条、重新插拔内存条、检查内存兼容性、升级 BIOS 版本。
软件配置问题¶
症状特征:
- 错误发生在特定驱动模块
- 调用堆栈指向第三方驱动
解决方法:
系统环境问题¶
解决方案:
- 检查 VMware 知识库
- 升级到最新补丁版本
- 应用临时修复方案
检查要点:
- 虚拟化功能是否开启
- 内存映射设置
- CPU 省电模式配置
预防措施¶
硬件层面¶
定期维护计划:
- 每月检查:CPU 温度、内存使用率
- 每季度维护:清洁散热器、检查风扇
- 每半年检查:内存诊断、硬盘 SMART 信息
- 每年更换:导热硅胶、UPS 电池
监控告警设置:
# 设置硬件监控告警
esxcli system settings advanced set -o /Config/HealthCheck/Enable -i 1
# 配置 SNMP 监控
esxcli system snmp set --enable true
esxcli system snmp set --communities community_name
软件层面¶
系统配置最佳实践:
定期更新策略:
- 关注 VMware 安全公告
- 测试环境验证补丁
- 分阶段生产环境部署
- 建立回滚预案
监控和备份¶
关键监控指标:
| 监控项目 | 正常范围 | 告警阈值 | 检查频率 |
|---|---|---|---|
| CPU 使用率 | < 80% | > 90% | 实时 |
| 内存使用率 | < 85% | > 95% | 实时 |
| 存储延迟 | < 20ms | > 50ms | 每分钟 |
| 网络丢包率 | < 0.1% | > 1% | 每分钟 |
| 系统温度 | < 70°C | > 80°C | 实时 |
备份恢复策略:
# ESXi 配置备份
vicfg-cfgbackup -s esxi-host-ip -f esxi-config.tar.gz
# 虚拟机配置备份
vim-cmd vmsvc/snapshot.create <vmid> backup-snapshot
# 定期完整备份
ghettoVCB.sh -a -g ghettoVCB.conf
故障案例分析¶
案例 1:内存 ECC 错误¶
故障现象:
排查过程:
# 1. 查看内存错误日志
grep -i "ecc" /var/log/vmkernel.log
> 2024-01-15T14:32:20.456Z cpu0:12345)NMI: NVRAM: Single-bit ECC error detected
# 2. 检查内存插槽
smbiosDump | grep -A 10 "DIMM_A1"
> Memory Device: DIMM_A1, Size: 16384 MB, Type: DDR4, Speed: 2666 MHz
# 3. 内存诊断测试
# BIOS 内存测试发现 DIMM_A1 存在错误
解决方案:更换 DIMM_A1 内存条,问题解决。
案例 2:第三方网卡驱动冲突¶
故障现象:
排查过程:
# 1. 识别问题驱动
esxcli software vib list | grep rtl8125
> rtl8125 1.0.0-1 Realtek PartnerSupported
# 2. 查看网卡错误
esxcli network nic stats get -n vmnic1
> Errors: 12345 packets dropped
# 3. 移除问题驱动
esxcli software vib remove -n rtl8125
解决方案:使用 VMware 官方兼容的网卡驱动,系统恢复稳定。
故障诊断工具¶
命令行工具¶
系统信息收集:
# 生成系统诊断包
vm-support -w /tmp/ -d 7
# 硬件信息导出
esxcli hardware platform get > hardware-info.txt
esxcli system version get > version-info.txt
日志分析脚本:
#!/bin/bash
# psod-analyzer.sh - ESXi 紫屏日志分析脚本
echo "=== ESXi PSOD 日志分析 ==="
echo "分析时间: $(date)"
# 检查最近的异常
echo -e "\n=== 最近错误日志 ==="
grep -i "exception\|panic\|psod" /var/log/vmkernel.log | tail -20
# 硬件错误统计
echo -e "\n=== 硬件错误统计 ==="
grep -c "NMI\|MCE\|ECC" /var/log/vmkernel.log
# 内存相关错误
echo -e "\n=== 内存错误详情 ==="
grep -i "memory\|dimm" /var/log/vmkernel.log | tail -10
第三方工具¶
RVTools:虚拟化环境信息收集 vSphere Health Check:系统健康评估 VMware Log Insight:日志集中分析
诊断总结
ESXi 紫屏问题的诊断需要系统性方法,从错误信息解读到硬件检查,再到软件配置验证。建立完善的监控机制和定期维护计划,可以有效预防此类严重故障的发生。遇到复杂问题时,及时收集诊断信息并寻求专业技术支持。
技术支持资源¶
如实在遇到不能解决的问题,可在 VMware 官方资源中查找,其他人有没有出现过类似的问题,没有的话,就直接提出问题,不要害怕语言问题。
VMware 官方资源¶
- 知识库:kb.vmware.com
- 社区论坛:communities.vmware.com
- 技术支持:通过 vSphere Client 提交 SR
诊断信息收集¶
提交技术支持时,需要收集:
- 完整紫屏照片
- vm-support 诊断包
- 硬件配置清单
- 故障发生时间和频率
- 最近的系统变更记录
紧急处理建议
- 首要原则:保障数据安全,避免二次故障
- 记录优先:详细记录故障现象和错误信息
- 分步排查:从软件到硬件,逐步排除故障原因
- 寻求帮助:复杂问题及时联系专业技术支持